TDM Platform Overview
The Enov8 Test Data Management (TDM) solution focuses on addressing real Personally Identifiable Information (PII) risks, ensuring that the highest-risk PII is masked quickly and effectively, thereby reducing the risk associated with less identifiable personal information.
TDM follows a "just enough" philosophy, prioritising the masking of key PII data such as:
- Name (First Name, Last Name, Full Name, and Organisation Name)
- Email Address
- Street Address
- Date of Birth
- Telephone Number
- Credit Card Number
- ABN/ACN
TDM is performance-engineered to target and obfuscate high-risk data sources, making them immediately available for use or redeployment. It is designed to be an all-in-one tool capable of performing Profiling, Masking, and Validation (Audit) of your data within hours, in contrast to traditional methods that often take weeks or months.
This guide will provide an overview of how to navigate and perform key tasks within the Enov8 Test Data Management solution.
Workflow Architecture
New Data Source Connection Workflow
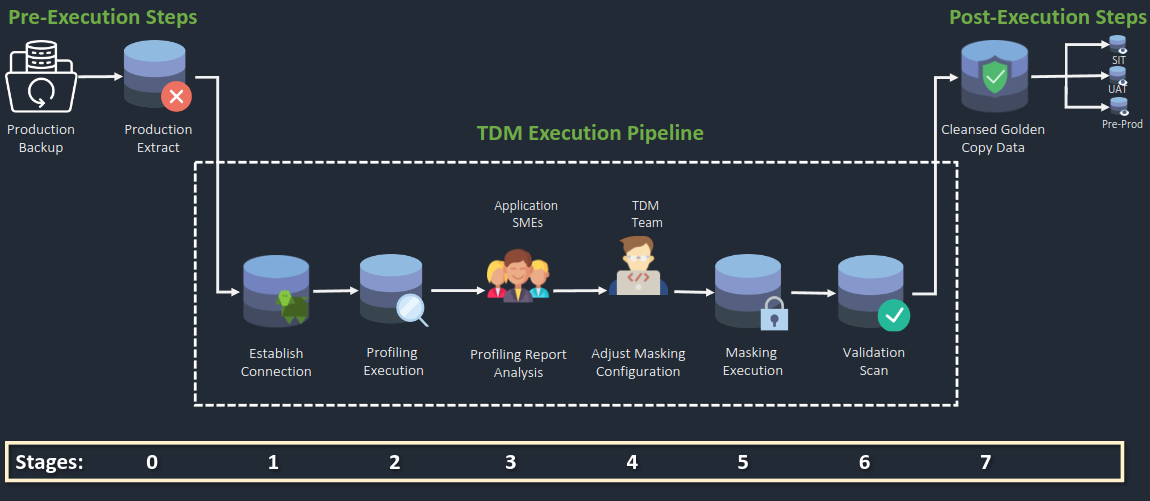
The workflow of the TDM Pipeline is separated into 7 phases. The first phase being the preparation of the database into the staging environment, steps 1-6 include the operations within the staging environment and finally the 7th stage includes the utilisation of the cleansed golden copy.
Pre-Execution Steps
Stage 0
-
Collaborate with the DBA to prepare a copy of the source/production database.
-
Load the backup into the staging environment.
TDM Pipeline Execution
Stage 1: Establish Connection
Establish a connection to the datasource.
Stage 2: Profile Data Source
Profile the data source to identify its characteristics and discover any PII.
Stage 3: Analysis of Profile Report
Collaborate with the Application Subject Matter Expert (SME) to analyse the profile report.
Stage 4: Adjust Masking Configuration
Adjust the automatically created masking configuration based on the analysis.
Stage 5: Masking Process
Perform a masking scan to obfuscate sensitive data.
Stage 6: Validation Scan
Conduct a validation scan to ensure the effectiveness of the masking process.
Post Masking Steps
Stage 7
-
Utilise Masked Database
a. Use the newly masked database from the staged database as a cleansed database copy.
-
Deployment for Testing
a. Deploy the cleansed golden database for testing in environments such as SIT, UAT, and Pre-Production.
Existing Data Source Connection Workflow
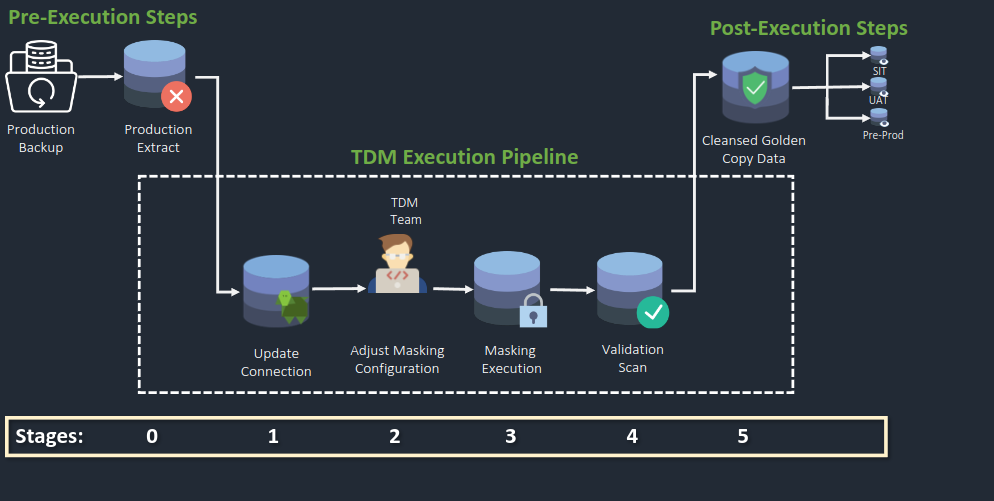
The existing data source connection follows a similar format yet excludes the initial stages of profiling data.
Pre-Execution Steps
Stage 0
-
Collaborate with the DBA to prepare a copy of the source/production database.
-
Load the backup into the staging environment.
TDM Pipeline Execution
Stage 1: Update Connection
Update data source connection.
Stage 2: Adjust Masking Configuration
Adjust the masking configuration based on the updated data source.
Stage 3: Masking Process
Perform a masking scan to obfuscate sensitive data.
Stage 4: Validation Scan
Conduct a validation scan to ensure the effectiveness of the masking process.
Post Masking Steps
Stage 5
-
Utilise Masked Database
a. Use the newly masked database from the staged database as a cleansed database copy.
-
Deployment for Testing
a. Deploy the cleansed golden database for testing in environments such as SIT, UAT, and Pre-Production.
Config Workflow
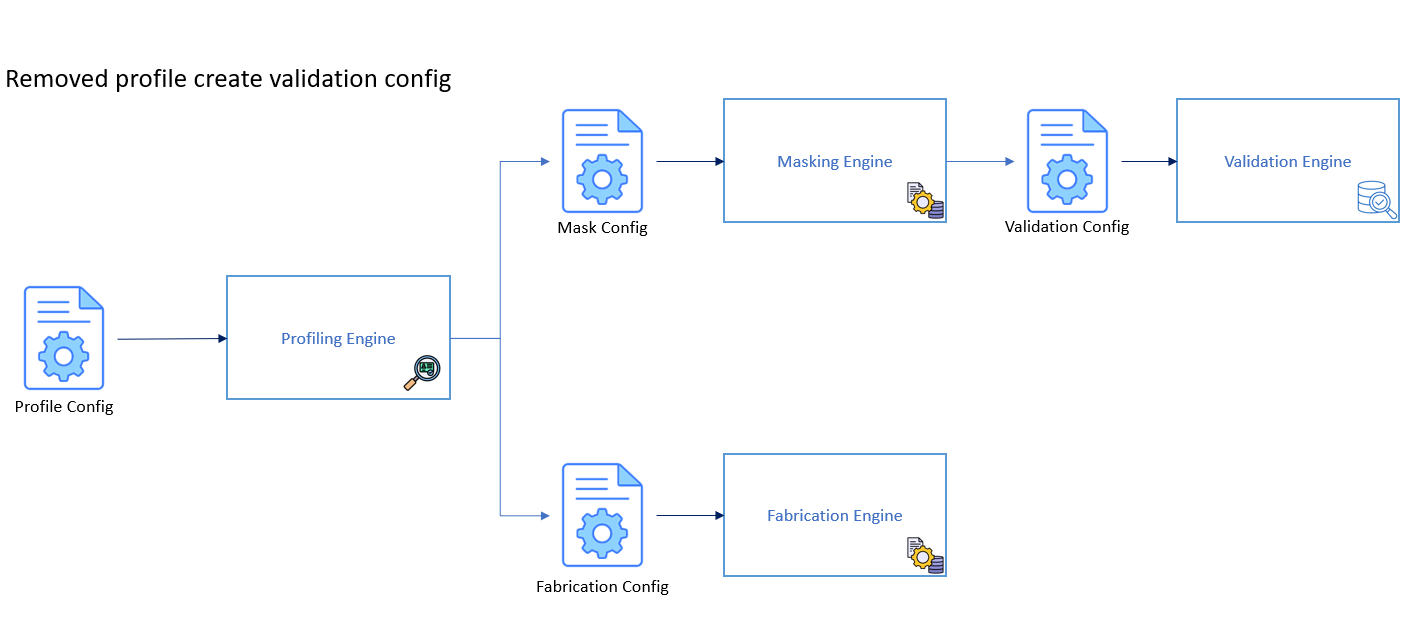
A config is necessary for the execution of a TDM script. However, if the correct flow of the TDM pipeline is utilised, the configs will be auto-generated by a TDM scan.
Profiling Config
The profiling config will hold details such as the patterns it is required to search for, the tolerance, and the depth it should follow. It is a set of instructions on what PII data to find and how it should search for it. For most clients, this is worth altering to fit their respective databases.
Mask Config
The masking config will be auto-generated after profiling is executed. It will provide the masking application details on the PII data found, including what column, what table, and what database. It will represent all information that should be obfuscated.
Fabrication Config
The fabrication config, similarly to the mask config, will be generated by profiling. However, it will dive into the schematics of the database profiled so it can be replicated when fabrication is executed. It will include the patterns found, schema structure, and row count to effectively duplicate the database through SQL queries.
Validation Config
The validation config will be auto-generated by the masking engine. It will include details of each masked column with the respective pattern used. It will additionally include a threshold value to support the execution of the validation engine. Using this information, the validation engine will then compute if all PII data has been masked effectively.
Note: After the generation of a config, it may be modified to refine the accuracy of the config.